
The High-Scale vs. Low-Scale Self-Assessment
The idea of ‘high-scale’ vs ‘low-scale’ isn’t rooted in numbers. I prefer to think of it as a set of behaviors. Before we dive deeper, let’s see how your team operates when alert first arrives.
The Checklist
- [ ] The Reflex: During an incident, is your browser history filled with Grafana or Datadog links rather than GitHub PRs?
- [ ] The Vocabulary: Do you say "P99" more than "Stack Traces"?
- [ ] The Priority: Is "getting back to green" (Mitigation) more urgent than "fixing the bug" (Resolution)?
- [ ] The Dependency: Do your incidents often originate in services you didn't write and can't see?
- [ ] The Event: Does traffic spike 10x during specific events, breaking code that hasn't changed in weeks?
If you checked these boxes, Bacca is built for you.
If you didn’t, that is okay too. It simply means you are solving a different type of problem that requires a different set of tools.
Two Different Problems, Two Different Workflows
Within the AI SRE space, at Bacca we believe there are two structurally distinct problem types that require different AI solutions. These differences aren't just about company size; they emerge from how engineering teams operate and the nature of the business.
Many of our competitors attempt to build a "General Purpose" AI that covers everyone. We believe that is a mistake. Because the problems are different, the human workflows used to solve them are different today, which warrants different AI solutions too. To understand why, you have to look at the structural divide in the discipline.
1. The Low-Scale Environment (The "Code" Problem)
This is common in enterprise B2B space. Traffic is sparse, but every request is high-value. Incidents are usually singular and deterministic.
- Think: “A user hit a bug—how do I fix it fast?”
- The Focus: They are searching for a syntax error, a logical flaw, or a bad commit.
- The Workflow: Engineers move directly into things like GitHub or Sentry to patch code-level issues.
- The AI: You need tools like Cursor or Claude Code to help you fix the syntax or logic bug.
2. The High-Scale Environment (The "System" Problem)
This is the world of large scale consumer-facing systems (e.g., Snap, TikTok, Uber). Incidents often emerge as aggregated service degradation affecting millions of users.
- Think: “Is the system behaving normally?” (This typically occurs at millions of users, though complexity isn't strictly limited to user count.)
- The Focus: They are looking for signals to isolate the problem to the root cause. The code likely hasn’t changed since the last deploy, but the environment has.
- The Workflow: The operation begins with triage across dashboards rather than debugging individual requests. The goal is determining where the bleeding is, not which line of code is wrong.
- The AI: You don't need a coding assistant. You need an AI SRE that understands system architecture, dependencies, and reason through the massive amount of telemetry data to find the needle in the haystack, like how your senior engineers do.
Most of today’s AI tools are built for the Code-Centric Workflow. But if you are managing a high-scale environment, fixing code is usually not the first thing you need. You need a tool that explains why the system is bleeding.
Why Code Alone Can't Save High-Scale Systems
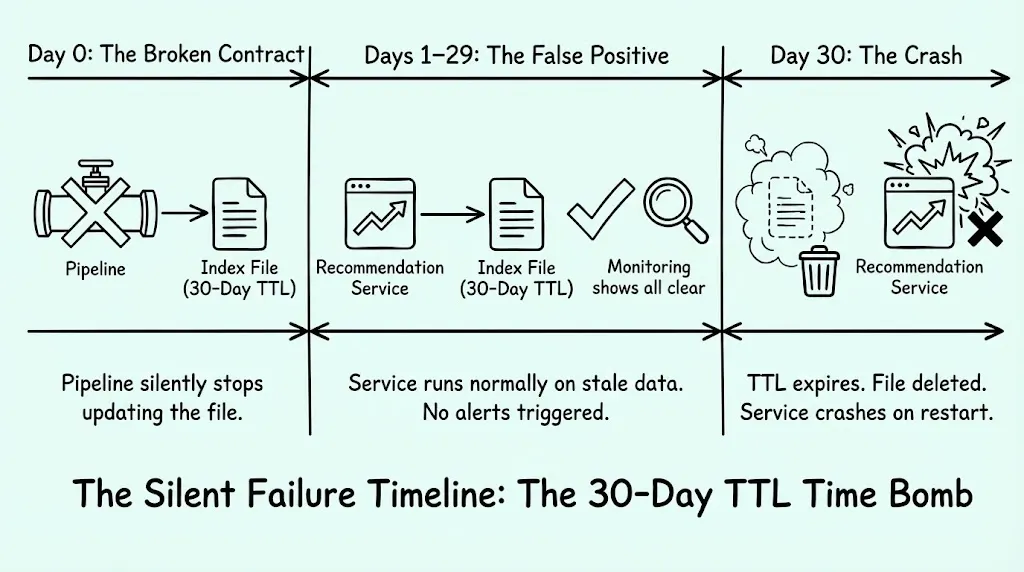
The 30-Day Time Bomb
I remember a specific incident from my time at Snap that illustrates why code-focused tools fall short in system-focused incidents.
We had a critical recommendation service that relied on a data file from an offline pipeline. The contract wasn't an API call; it was a file transfer. The service required this file to be loaded into memory at startup.
The catch? The data file had a 30-day TTL (Time-to-Live). The pipeline generating the file began failing silently. For 29 days, the service operated normally because the old file remained in place. On day 30, the file hit its TTL and was deleted. Suddenly, the service crashed upon restart.
No amount of staring at VS Code would reveal this bug. The code was fine. The environment—a data dependency spanning a month—was the issue. A developer sees perfect code; the customer sees a 500 error.
Mitigation First
Because the problems are different, our response must change. In high-scale engineering, we need to think less about "code bug fixing" and more about "incident mitigation."
Mitigation is the Tourniquet.
This is the goal during a P0 incident. The patient is bleeding out. I need to understand the root cause well enough to apply the right mitigation, but I’m usually less worried about the specific line of code that triggered it. Actions here are rough and might temporarily degrade the user experience, but they keep the system alive:
- Rolling back a deploy.
- Flipping a feature flag to disable a component.
- Scaling up the service or database layer.
- Load Shedding (dropping 10% of traffic to save the other 90%).
The Human Bottleneck: The "Guru" Trap
High-scale incidents often create the 90/10 Problem. In many organizations, 10% of the responders (the "Gurus") drive 90% of the progress. These are the senior engineers who hold the "Tribal Knowledge". In high-scale environments, the majority of operational knowledge doesn't exist in code. It lives in:
- Confluence pages documenting "known issues" from two years ago
- Jira tickets describing obscure dependency chains
- Slack threads where someone figured out that Service A breaks when Service B's retry logic kicks in
- Most importantly, the heads of your expert engineers
These experts remember which dashboard to check first. They know how systems interoperate—not because they write the code, but because they've lived through the incidents. They form hypotheses based on symptom patterns they've seen before: "Error rate spike + database latency + time of day = probably the batch job competing for connections."
This creates a single point of failure. If your Guru is on a plane during the outage, the system stays down. We manage systems too complex for any single human brain to map entirely, relying on the memory of a handful of exhausted experts.
This is the fundamental reason why code-centric tools fail in high-scale environments. When the critical knowledge isn't in your codebase—when it's scattered across docs, tickets, conversations, and human memory—an AI that only reads code is essentially blind to 90% of what matters during an incident.
BACCA is purposely-built for the High-Scale environment.
Bacca exists for one reason: high-scale incidents are not debugging problems — they are triage problems. My co-founders and I built Bacca because we’ve solved high-scale problems at companies with hundreds of millions of daily active users. We realized there was no tool purposefully built for the High-Scale Workflow.
Bacca is purposely designed for high-scale environments. We moved away from generic AI wrappers and simple RAG (Chatting with your Docs) because high-scale systems need certainty, not guesses.
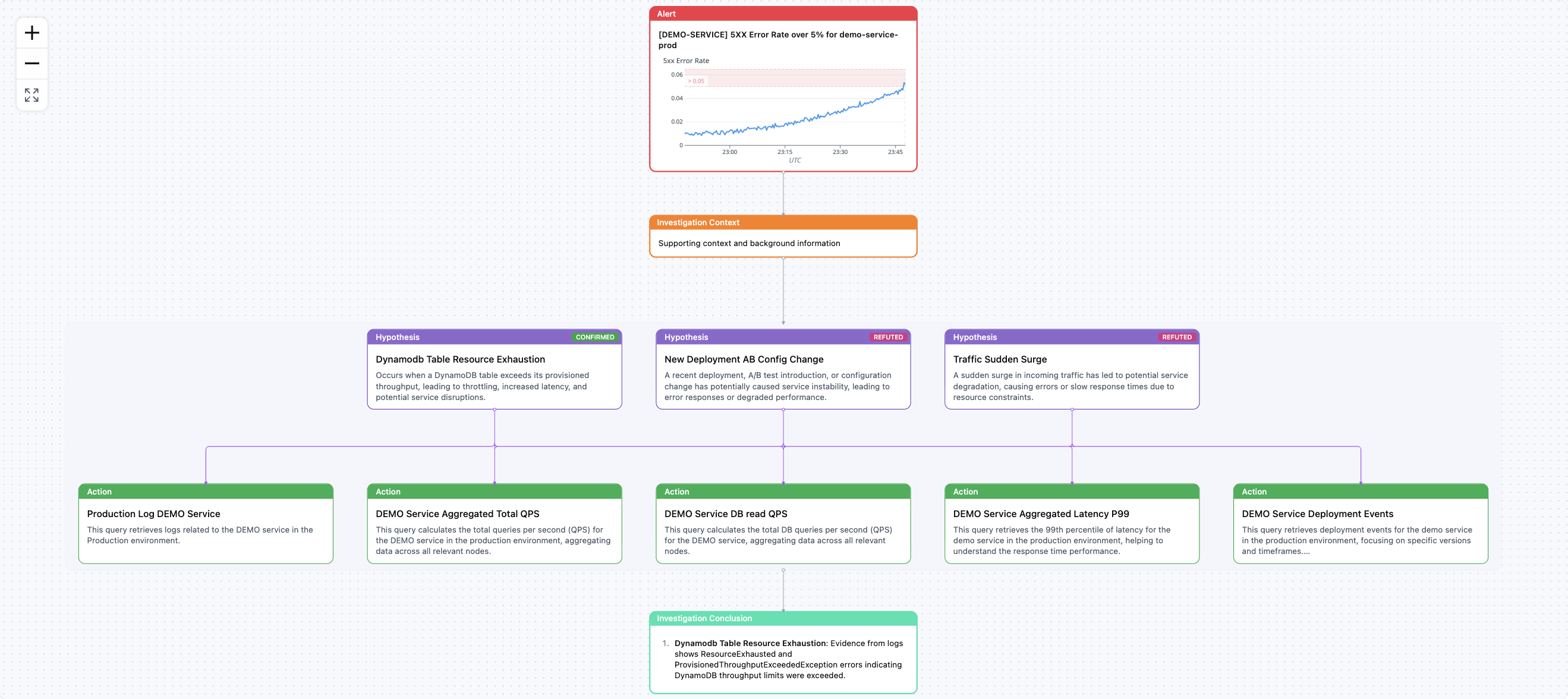
The Core: A Living Knowledge Graph of Tribal Operational Memory
The hardest part of incident response isn’t lack of data — it’s lack of context.
In high-scale organizations, the most valuable knowledge doesn’t live in code. It lives in the accumulated operational history of your company: past incidents, hidden dependencies, unwritten rules, and hard-earned responder intuition.
Bacca ingests this institutional memory and learns it as a knowledge graph — mapping systems, services, past incidents, and human decisions into a structure the AI can reason over.
So instead of starting from scratch every outage, Bacca starts from what your organization already knows. This moves Bacca from "searching" to hypothesis-driven triaging. Instead of dumping a thousand logs on you, Bacca acts like an expert:
"Hypothesis: The recommendation service crash is likely caused by a missing index file. I found a correlation with a silent failure in the 'data-pipeline-alpha' job from 30 days ago."
Optimized for Observability-Native Reasoning, Not Standalone Spikes
Modern observability platforms generate an endless stream of metrics, traces, and logs. But in high-scale systems, incidents rarely announce themselves as a single clean error. They emerge as subtle patterns: weak signals compounding across services, dependencies, and time.
- A CPU spike alone doesn’t tell you much.
- An error rate blip alone is rarely the story.
Bacca is purpose-built to retrieve and interpret observability data in that context. It looks beyond isolated spikes to detect trends, correlations, and anomaly clusters that point toward the underlying failure mode.
This moves incident response from “staring at dashboards” to system-level reasoning. Instead of surfacing raw signals, Bacca forms an interpretation:
"This latency regression is not local. It is spreading downstream from the cache layer, correlated with an increase in retry volume, and matches the signature of a prior saturation event."
Because at scale, the signal is never just the spike. The signal is the system.
Own Your Problem Type
The AI SRE industry wants you to believe that one tool can do it all.
If you are building a low-scale B2B app, use the code-centric tools. They are magnificent.
But if your nightmares are about latency cascades, deadlocks, and silent data failures, stop pretending you have a coding problem.
When the platform is down, perfect code won't save you. You don't need a better writer; you need a better operator.
Eric Lu, Founder & CEO
we will contact you soon