

You know the feeling. PagerDuty fires at 3 AM. Your phone lights up the room. You drag yourself out of bed, open your laptop, and spend the next two hours chasing logs, staring at dashboards, and trying to figure out what actually broke.
I have been there. At Snap, I lived through a massive failure across multiple distributed micro-services. The engineering team spent four hours searching for the context of the breakage, before we even started fixing anything. We were exhausted. The physical toll of manual triage is real, and it compounds over time in ways that destroy teams.
For engineers running high-scale systems, that’s just another Tuesday.
But it shouldn’t have to be.
Today, we are announcing that Bacca is officially your Tier-1 on-call. We take the midnight pages. We do the investigation. We mitigate the issue. You stay asleep.
Watch the demo below. See Bacca wake up at 3 AM, handle a real page, and resolve the issue while your team sleeps.
There will always be incidents. That is the simple reality of operating software at scale. Complex systems break, and writing perfect code is unrealistic. The question has never been whether something will break. The question is who is on the front lines, and what that costs your team.
From today onward, Bacca is the one holding the hose.
Two Years to Get Here. Here Is Why It Took That Long.
A fully autonomous, self-healing SRE agent has always been the goal. Not a tool that helps you firefight faster. A virtual team member that does the firefighting entirely, reliably, on its own.
But there is one thing standing between that vision and reality: Getting the root cause accurately.
RCA is the single most important input in the entire automation chain. You cannot safely take a mitigation action without knowing exactly what broke and why. If the root cause is wrong, the fix is wrong. And in a P0 incident touching millions of users, a wrong fix is often worse than no fix at all.
I know this because we tried to skip it.
Early on, we tried to bypass the technical challenge of deep RCA entirely and jump straight to automated mitigation using historical failure patterns. The logic seemed reasonable: if this alert fired before and this action resolved it, do the same thing again. The results were flaky, unpredictable, and in some cases actively made things worse. You cannot build reliable automation on top of bad reasoning. That lesson set us back, but it made the path forward clear.
We also studied standard Retrieval-Augmented Generation models closely. RAG is unstructured and non-deterministic. It hallucinates when system state changes, which is precisely when you need it most. We rejected it.
Instead, we built structured Knowledge Graphs. They map the exact, source-of-truth relationships between your load balancers, databases, and thousands of micro-services. They give the agent deterministic, actionable context, not probabilistic guesses over raw telemetry. Telemetry tells you what is happening. A Knowledge Graph tells you why, and does it reliably.
So we went uphill. We spent two years getting root cause identification as accurate as it could possibly be. Not mostly right. Not good enough for low-stakes systems. Accurate enough to act on in production.
We are now at over 95% RCA accuracy across high-scale, highly distributed environments. That number has been validated across thousands of real incidents, live cascading failure scenarios, and real systems with millions of users depending on them.
95% RCA accuracy is not the summit. It is base camp. It is what makes everything above it safe to build.
What Bacca Actually Does at 3 AM
Think of Bacca as a brilliant remote engineer who lives natively inside your Slack workspace, operates at machine speed, and never sleeps. Here is the exact workflow.
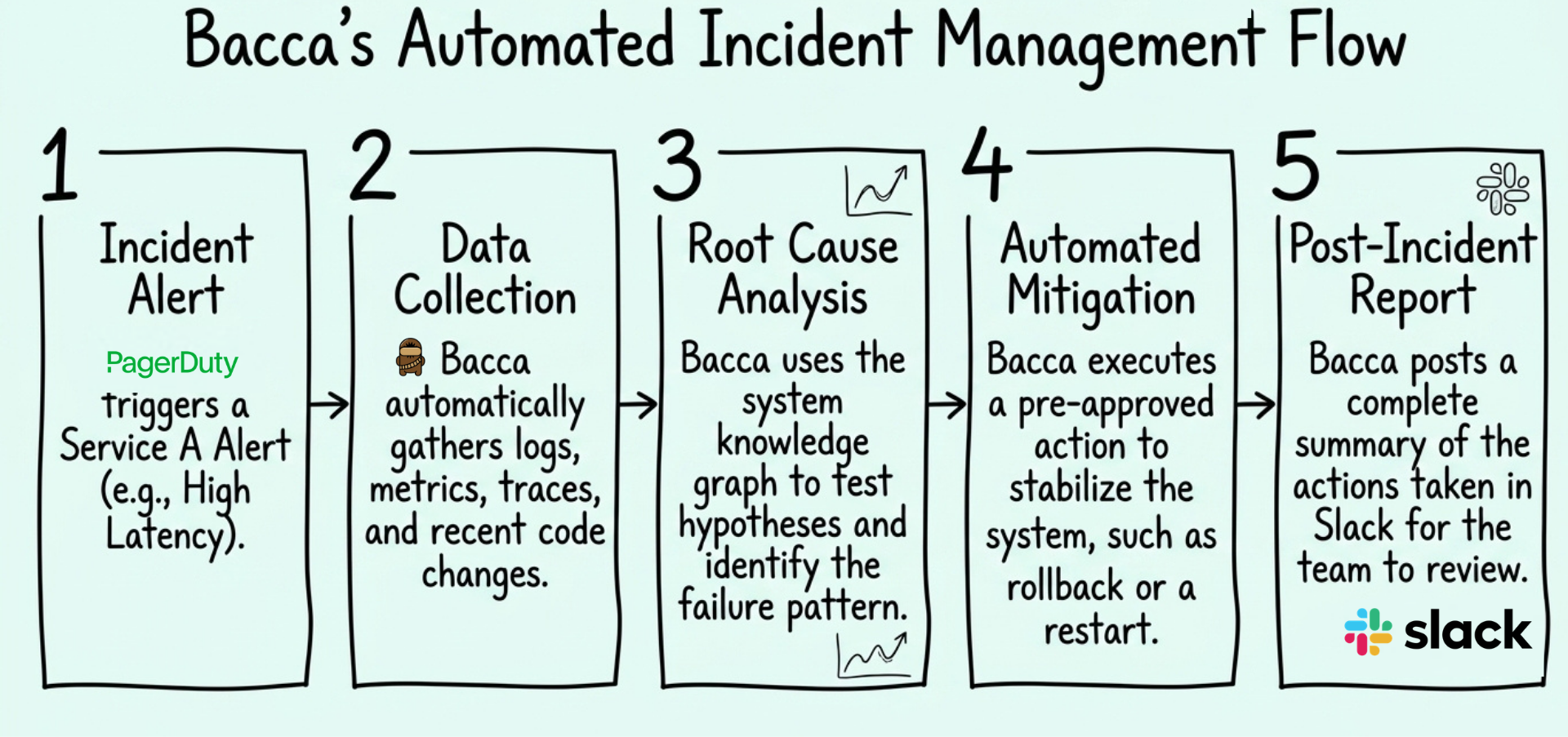
PagerDuty fires. Your team is asleep. Bacca is not.
Bacca jumps onto the incident instantly and starts triaging. Not just historical context, it pulls distributed tracing data, reads your error logs, looks at anomaly metrics, reviews recent infrastructure changes, and directly inspects the relevant parts of your codebase.
From there, it runs through competing failure hypotheses using your team's domain knowledge as the filter. This is where the Knowledge Graph earns its place. In almost every high-scale environment, 90% of the operational context lives in the heads of 10% of the engineers. When a P0 hits at 3 AM, you typically wait for that one senior staff engineer to wake up and recognize the failure pattern. Bacca already knows the pattern. It does not wait for a human to point it in a direction.
It reaches a conclusion with over 95% accuracy. Then it acts.
Using a set of pre-approved mitigation actions your team has already signed off on, Bacca resolves the issue. A rollback if a recent deploy is the culprit. Load shedding if the upstream is overwhelmed. A targeted restart if a service has gone sideways.
One important distinction: mitigation is the tourniquet. The goal during live incident response is to stop the bleeding, not to write the perfect permanent fix. The underlying code resolution happens during normal business hours when your engineers are rested and sharp. Bacca applies the technical tourniquet immediately, so the situation does not deteriorate while someone is still waking up.
You wake up to a full report. What triggered, what was investigated, what hypotheses were ruled out, what action was taken, and why. One of our early users described it well: he walked his dog “with the energy of a puppy” while talking about how Bacca had done his job while he slept. You open Slack over your morning coffee and read the post-mortem. Your on-call engineer slept through the night.
Bacca does not help you fight fires. It fights the fire for you.
On Safety, Guardrails, and Not Going Rogue
The first thing every engineering team asks when they hear "autonomous production actions" is some version of the same question: what stops it from making things worse?
It is the right question. A rogue script can drop a production database. Handing the keys to an autonomous agent requires real trust, and trust must be earned incrementally.
Bacca only takes actions your team has explicitly approved. There is no autonomy without opt-in. You define the boundaries. Bacca operates inside them and nowhere else.
That control is granular. You configure approved actions at the team level, the service level, or down to the individual monitor. A few principles we recommend:
- Establish explicit opt-in boundaries for every micro-service before enabling autonomous actions
- Restrict mitigation to reversible state changes only
- Maintain an immutable audit log of every executed command
If you want Bacca to complete the full investigation and propose a mitigation strategy, then pause for a human to approve before touching anything, it does exactly that. If you want it to act autonomously within a pre-approved set of actions without waking anyone up, it does that too. You choose the mode. You expand the blast radius as trust builds, on your timeline, at your comfort level.
But what happens if Bacca tries to fix a problem, and the fix isn't effective? Replacing yourself as Tier-1 naturally raises a worst-case scenario concern: Am I completely removing myself from the loop? Will a serious issue slip through the cracks silently?
To build trust and ensure this never happens, Bacca is built with a strict, configurable default escalation path. Handing over the pager does not mean adopting a "fire and forget" mentality. You define what constitutes a high, medium, or low-impact incident—whether by the number of affected users, impacted services, or your own custom prompt definitions.
- High Impact: For critical issues (e.g., 100% of users are experiencing trouble), Bacca’s default behavior is to page you immediately. It will simultaneously work to isolate the incident, but it will not wait to wake you up.
- Medium and Low Impact: For lower severity incidents, Bacca intercepts the page and acts as your Tier-1. It investigates and deploys your pre-approved fix. Crucially, it then monitors system metrics to verify the resolution actually took effect. If the issue is not fully resolved within a configurable timeframe (e.g., X minutes, defaulting to 30 minutes), Bacca automatically abandons the autonomous track and escalates to a human.
Every hypothesis Bacca formed, every action it considered, every decision it made, all of it is logged. Full audit trail. Fully explainable. You will never have to guess why Bacca restarted a pod.
The goal is not to remove humans from the loop permanently. The goal is to only involve humans when their judgment is actually needed. That distinction matters, especially at 3 AM.
What We Are Building Next
With 95% RCA accuracy proven and autonomous mitigation running in production, we are aggressively expanding the remediation surface, more action types, more system integrations, and more coverage across the failure modes that actually wake your team up at night.
The end goal has not changed since day one: a fully autonomous AI SRE that operates and repairs high-scale software without human intervention. Not a copilot or an assistant. An engineer that knows your system, learns with every deploy, and acts when things break.
This is not a theoretical roadmap. The core technical foundation is running in production today.
We had to solve the diagnostic problem before we could safely solve the remediation problem. That sequence was not accidental. You cannot skip it. The 95% accuracy is what makes the autonomy trustworthy. Remove it, and you are just automating bad decisions at machine speed.
The Fire Is Coming. It Always Does.
The incident management market is largely focused on orchestration and process management, automatically generating tickets, paging the right escalation chain, spinning up Zoom war rooms. That is useful work.
But none of it fights the fire. A war room just means you have twenty tired engineers staring at Datadog together.
There is also a broader dynamic worth naming. The industry right now is obsessed with vibe coding, the idea that generating code is the entire job. It is not. Writing code is the easy part. Operating it at high scale is the actual hard work, and it is largely invisible. Development versus operations is a six-lane superhighway funneling into a two-lane bridge. You can ship code faster than ever. You still have to keep the infrastructure running when millions of users hit that new endpoint at 2 AM on a Saturday.
Your systems are only getting more complex. Distributed micro-services, cascading dependencies, growing user bases. The alert volume is not going down. Your team's bandwidth is.
Bacca is purpose-built for that reality, specifically for high-scale platforms where the standard playbooks do not hold and the blast radius is not forgiving. Your engineering team no longer has to pay the price for that bottleneck with their nights and weekends.
If you are tired of being the frontline firefighter, this is what we built.
👉 Book a demo or schedule a chat with the team.
👉 Watch the demo video to see a real 3 AM incident handled from page to resolution, no humans required.
Eric Lu
Founder & CEO, BACCA.AI
we will contact you soon